

Vediamo di fare un pò di ordine e capire come si comportano nel calcolo distribuito.
Benchmark con Crysis ne trovate a tonnellate, benchmark sui progetti di distributed computing no, ma vabbè
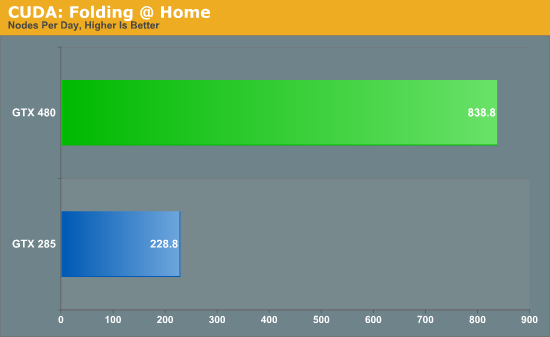
Cominciamo con Folding, noto progetto che sulle Nvidia fa faville da sempre
Qualcosa non quadra. Decisamente no.Ma vabbè, i risultati della 480 coincidono quindi vabbè... sembra che queste Fermi su Folding facciano faville.
Ricordo però che questi dati sono stati presi usando come bench una WU campione spedita da Nvidia e non WU "reali" quindi insomma, i risultati possono essere un pò più alti del reale.
http://forums.bit-tech.net/showthread.php?t=185421
Passiamo agli altri progetti. Finora info sugli altri 3 non ce ne sono, visto che tutti questi giornalisti che ricevono le schede in anticipo mica vanno a testarle lì e anzi, oso dire che come vedrete in seguito mi sa che se l'avessero fatto Nvidia li prenderebbe a calci nel didietroAt the moment you can't truly fold on a GTX 480 - the scores you've seen in some reviews (not ours) are based on a client and WU supplied by Nvidia, which being proper indepedently minded journalists we don't trust.
Even though there isn't a proper Stanford client for it, there are still two good reasons not to get exicted about GTX 480 - it consumes a ludicrous amount of power and runs ridiculously hot.
Personally I'd never be happy to have a GPU running at 92C in one of own PCs.
Su Milkyway, che richiede la doppia precisione, sorgono sospetti sulle performance
Inoltre per vari motivi di ottimizzazione dei client di entrambe le schede (cosa che su Folding MANCA PER LE ATI che hanno un client NON OTTIMIZZATO e da cani (per stessa ammissione dello staff eh, non invento io)) le Nvidia storicamente su Milky e Collatz stanno sotto le ATI. Entrambi i client per le 2 marche sono ottimizzatissimi quindi è proprio un fatto.From Hexus.net
Compute machine and multitasking. But GTX 4x0 is crippled
As much of a general-purpose computer as a GPU, the parallel architecture is also designed for the high-performance computing segment in mind. The enhanced cache structure, detailed above, helps with general computations, and GF100's adherence to the IEEE 754-2008 floating-point standard means that it can run high-accuracy tests (double-precision support) at an increased rate when compared to anything NVIDIA has designed before.
Delve a little deeper, handily not mentioned in any briefing, and NVIDIA is limiting the double-precision speed of the desktop GF100 part to one-eighth of single-precision throughput, rather than keep it at half-speed, as per the Radeon HD 5000-series. We'll have to wait for the Tesla parts before that's restored to Radeon-matching levels.
A meno di un miracolo, anche le Fermi rimarranno "ferme" dietro alle ATI
Su GPUGrid non si sa ancora niente, per ora ci macinano solo le Nvidia e sarebbe interessante sapere le prestazioni delle 470 e 480 su quel progetto













 Se le schede sono un fail lo si dice e si lulla
Se le schede sono un fail lo si dice e si lulla
